
1·
24 hours agoIl semble possible d’avoir des “bridges” entre blusky et le fediverse, mais la question est de savoir à quels point ils dépendent du bon vouloir the bluesky et sont à la merci d’un API change unilatéral.
Il semble possible d’avoir des “bridges” entre blusky et le fediverse, mais la question est de savoir à quels point ils dépendent du bon vouloir the bluesky et sont à la merci d’un API change unilatéral.
Sauf erreur de ma part, il n’y a pas d’investisseur dans Wikipédia ou Internet Archive. C’est une différence fondamentale, leur business plan est uniquement fondé sur des dons. La seule façon d’éviter la merdification, c’est de n’avoir aucun acteur dans la structure qui espère se faire de l’argent avec. Et c’est simplement pas le cas de BlueSky.. Donc là ils sont cool ils ont pas de pub et ils vendent pas je pense encore les informations de leurs utilisateurs mais quand les gens qui ont mis 8 millions de dollars sur la table vont se rendre compte que vendre des noms de domaines ça ne rapporte pas tant que ça qu’est ce qu’ils vont faire? C’est ça la question
Aujourd’hui. Quand est-ce que le grand public va comprendre la séquence de la merdification des sites? Tu commences un site en étant cool et sans pubs, à perte, et quand tu as quelques millions d’utilisateurs, tu le vends “la mort dans l’âme” pour quelques millions à des gens qui transforment ça en pompe à fric à coup de pub. Rince, répète.
On a vu la façon dont Reddit a changé, la façon dont Twitter a évolué. Bluesky fait des promesse comme avait fait Google, a une structure “non profit” comme OpenAI. Et dans 10 ans on va se demander comment ça a pu péricliter à ce point…
C’est encore l’ancien CEO de Reddit qui le dit le mieux:
In addition, I am continually astounded that people sort of trust corporations like they trust people. We can talk all day about how the current team is trustworthy and we’re not in the business of screwing you, but I also have to say that you can never predict what happens. reddit could be subject to some kind of hostile takeover, or we go bankrupt (Please buy reddit gold) and our assets are sold to some creditor. The owners of corporations can change - look what happened to MySQL, who sold to Sun Microsystems, who they trusted to support its open source ethos - and then Sun failed and now it’s all owned by Oracle. Or LiveJournal, which was very user-loyal but then sold itself to SixApart (still kinda loyal) which failed and then was bought by some Russian company. I am working hard to make sure that reddit is successful on its own and can protect its values and do right by its users but please, you should protect yourselves by being prudent. The terms of our User Agreement are written to be broad enough to give us flexibility because we don’t know what mediums reddit may evolve on to, and they are sufficiently standard in the legal world in that way so that we can leverage legal precedents to protect our rights, but much of what happens in practice depends on the intentions of the parties involved.
https://www.reddit.com/r/blog/comments/1sndxe/comment/cdzcwdf/
Oui à la place il se fait financer par un cryptobro.
La technique peut s’améliorer, le rythme aussi surtout, encore un peu lent, mais qui s’améliore! L’écriture comique, c’est pas donné à tout le monde. Plein de courage à la personne qui fait ça!
J’ai aimé le “salut les connards!” de Macron. Complètement gratuit, complètement en ligne avec le perso.
Ou peut être qu’ayant réussi à se faire pas mal d’argent en vendant twitter à un facho, il prévoie de faire la même chose avec bluesky?
Je comprends vraiment pas comment c’est pas se refaire avoir par littéralement la même personne!
jlai.lu et /r/france ont le droit d’avoir des règles différentes.
Je dois avouer que je comprends pas: Bluesky c’est le créateur de Twitter derrière. Pourquoi espérer un dénouement différent?
Pareil: https://piaille.fr/@ktp_programming
Mais j’y suis pas souvent
Arrête de lancer gratuitement comme ça des idées que tu peux facturer 100k à la présidence via des cabinets de conseil!
Note que le privé, c’est pas forcément des société capitalistes, ça peut être des assoces ou des coops. Perso je commence à voir la résistance de ce coté là aussi. C’est un peu l’histoire des mutuelles et des premières caisses de prévoyance.
On pourrait commencer par le minstère du budget. Je doute qu’un LLM puisse faire pire que Bruno Le Maire.
Mais on sait très bien que l’équipe actuelle a pas l’intention de mettre plus d’argent dans la fonction publique. Que l’efficacité du dépôt de plainte, ils s’en foutent, et qu’ils veulent moins de fonctionnaires. Qu’ils le fassent en remplaçant par un truc qui a une chance de faire le boulot mieux au lieu de simplement fermer totalement le service, ça me parait évidemment préférable.

Les dogmes ça sert aryen.
Le choix c’est pas entre IA et police humaine parfaite, c’est entre IA et la police qu’on a, avec encore moins de budget.
On pourrait tout de même regretter que cela prenne la place des interprètes qui savent traduire bien au-delà des mots.
L’expérience de ma compagne japonaise c’est que la place dont tu parles est généralement vide et remplie par un fonctionnaire qui s’en fout et qui ne parle même pas anglais.
Quant aux benchmark, effectivement on parle de taux d’erreur entre 1% et 3% dans le cas des RAG.
Source?
Le problème des benchmarks, c’est qu’ils sont là pour tester des différences de performances entre modèles. Ils sont faits pour être durs plutôt que réalistes. Un benchmarks qui te donnerait 100% ou 99.99% de succès, on le jetterait à la poubelle car il ne permet plus d’évaluer les progrès, et on en assemblera un nouveau avec les 0.01% d’erreur.
Ce qu’on demande en l’occurrence, c’est d’avoir un taux d’erreur inférieur au taux humain. Ce qui me semble extrêmement atteignable vu le niveau des policiers.
C’est tous les mêmes.
On notera la classe que c’est que d’annoncer sa candidature depuis le banc des accusés au tribunal!
Note qu’on n’est pas sur /r/france ici, tu as le droit de modifier un titre trompeur pour dire ce qui s’est vraiment passé, à savoir qu’il a été condamné à verser cet argent et qu’il a demandé à avoir 10 ans pour le faire, donc il n’a pas du tout proposé de les verser, il a proposé de retarder le versement de la chose qu’il a été condamné à payer.
REND L’ARGENT!
Alors je comprends complètement le cynisme qu’on peut avoir autour de la hype que ces techniques engendre et d’autant plus quand elles sont mises en avant par nos génies du gouvernement, mais franchement vu l’état actuel de ces techno le dépôt de plainte c’est exactement ce dans quoi moi j’ai envie de les voir déployees.
Ça peut résoudre plein de problèmes qu’on a en ce moment. Je veux dire là le but c’est pas de faire un travail parfait c’est de faire mieux que le désastre total qui est l’accueil en commissariat aujourd’hui.
Faisable en ligne. Tout le temps ouvert. Parlant 40 langues. Ayant un vocabulaire bien supérieur à la moyenne des fdo. Capable de dérouler un entretien selon des instructions avec patience sans jugement dans la langue que vous voulez. Le code de la procédure sur un genou et Legifrance sur l’autre. Ça va pas résoudre tous les problèmes d’un coup de baguette magique mais celui du refus du dépôt deplainte je pense que ça peut le résoudre totalement.
D’après un benchmark d’OpenAI, aucun modèle ne produit de résultats factuellement corrects plus d’une fois sur deux.
Il faut comprendre un truc autour des histoires d’évaluation des LLM : des problèmes qu’on a c’est qu’ils sont trop bon bien meilleur que la plupart des benchmark qu’on a on est constamment obligé de faire de meilleur benchmark pour mesurer les différences entre les meilleurs modèles. C’est parce qu’ils ont ce problème qu’openai vient de sortir un benchmark particulièrement difficile pour ses modèles.
Ces benchmarks là ne mesurent pas une chose utile pour l’application dont on parle, ims mesurent le savoir brut d’un modèle et sa capacité à le sortir. Par exemple ne pas confondre la médaille d’or et la médaille d’argent aux épreuves du 110 m haie des JO de 1986 ou que sais-je.
Un modèle à qui tu donnes un texte au début de sa fenêtre de contexte et sur lequel tu lui poses des questions va aujourd’hui très très rarement faire des erreurs et seulement si tu lui poses des questions d’une façon un peu tordue. Je pense que si on peut toutes les métriques possibles on a pas grand chose à gagner à faire saisir une plainte par un policier que par un llm








:quality(70)/cloudfront-eu-central-1.images.arcpublishing.com/liberation/2HP6KTZK5VE7RJD73EXZMUFNTQ.jpg)



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
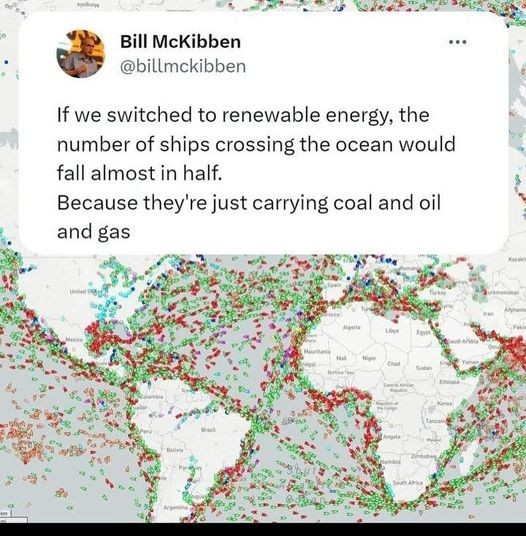
Faut voir: si la moitié des instances sont gérées par d’autres entités qui doivent toutes accepter un changement d’API pour que le réseau continue de marcher, un move comme celui de reddit devient moins probable.