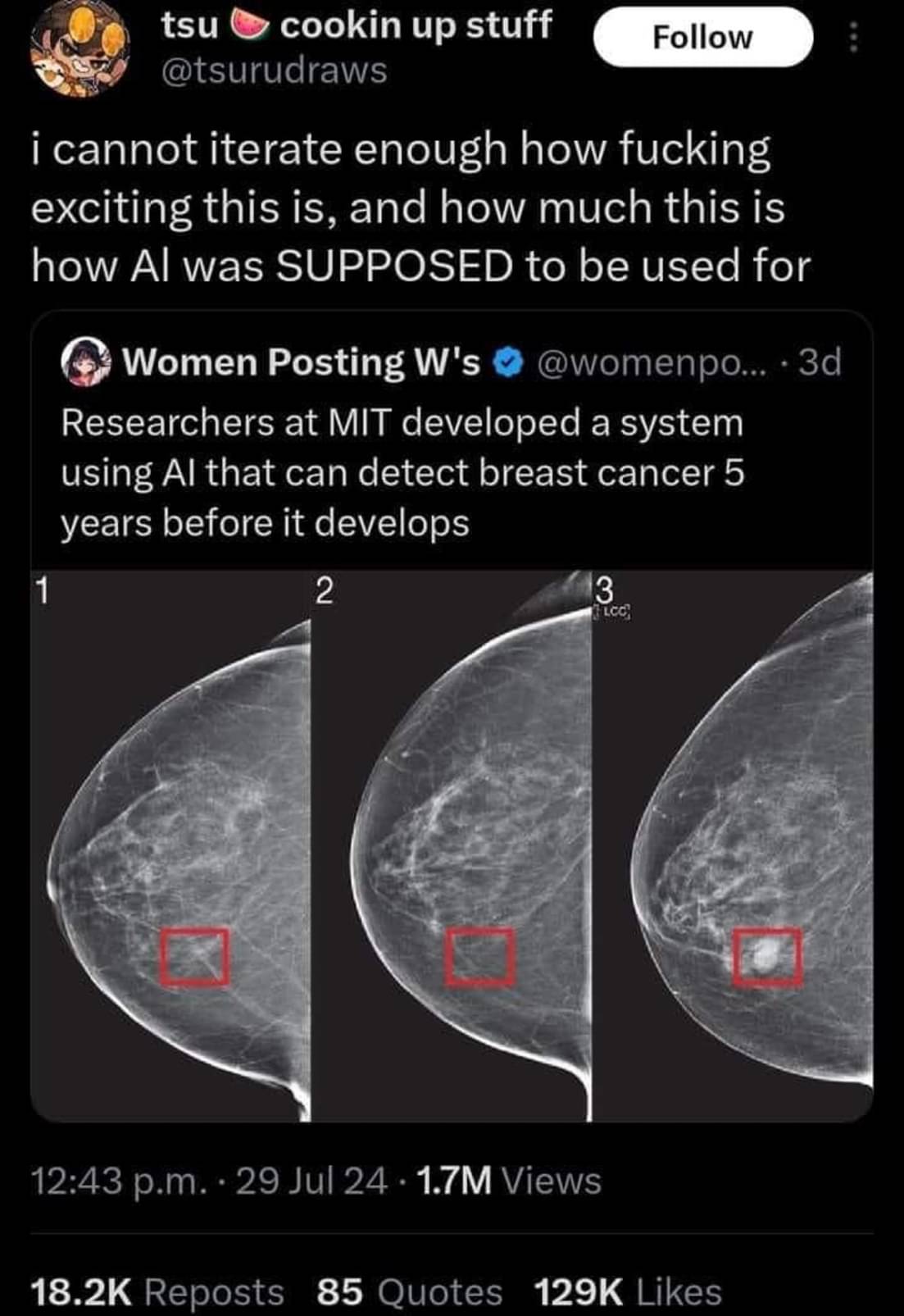
Unfortunately AI models like this one often never make it to the clinic. The model could be impressive enough to identify 100% of cases that will develop breast cancer. However if it has a false positive rate of say 5% it’s use may actually create more harm than it intends to prevent.
Another big thing to note, we recently had a different but VERY similar headline about finding typhoid early and was able to point it out more accurately than doctors could.
But when they examined the AI to see what it was doing, it turns out that it was weighing the specs of the machine being used to do the scan… An older machine means the area was likely poorer and therefore more likely to have typhoid. The AI wasn’t pointing out if someone had Typhoid it was just telling you if they were in a rich area or not.
That’s actually really smart. But that info wasn’t given to doctors examining the scan, so it’s not a fair comparison. It’s a valid diagnostic technique to focus on the particular problems in the local area.
“When you hear hoofbeats, think horses not zebras” (outside of Africa)
AI is weird. It may not have been given the information explicitly. Instead it could be an artifact in the scan itself due to the different equipment. Like if one scan was lower resolution than the others but you resized all of the scans to be the same size as the lowest one the AI might be picking up on the resizing artifacts which are not present in the lower resolution one.
I’m saying that info is readily available to doctors in real life. They are literally in the hospital and know what the socioeconomic background of the patient is. In real life they would be able to guess the same.
The manufacturing date of the scanner was actually saved as embedded metadata to the scan files themselves. None of the researchers considered that to be a thing until after the experiment when they found that it was THE thing that the machines looked at.
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.
What if one of those lower economic areas decides that the machine is too old and they need to replace it with a brand new one? Now every single case is a false negative because of how highly that was rated in the system.
The data they had collected followed that trend but there is no way to think that it’ll last forever or remain consistent because it isn’t about the person it’s just about class.
A false positive of even 50% can mean telling the patient “they are at a higher risk of developing breast cancer and should get screened every 6 months instead of every year for the next 5 years”.
Keep in mind that women have about a 12% chance of getting breast cancer at some point in their lives. During the highest risk years its a 2 percent chamce per year, so a machine with a 50% false positive for a 5 year prediction would still only be telling like 15% of women to be screened more often.
That’s just not generally true. Mammograms are usually only recommended to women over 40. That’s because the rates of breast cancer in women under 40 are low enough that testing them would cause more harm than good thanks in part to the problem of false positives.
Nearly 4 out of 5 that progress to biopsy are benign. Nearly 4 times that are called for additional evaluation. The false positives are quite high compared to other imaging. It is designed that way, to decrease the chances of a false negative.
The false negative rate is also quite high. It will miss about 1 in 5 women with cancer. The reality is mammography is just not all that powerful as a screening tool. That’s why the criteria for who gets screened and how often has been tailored to try and ensure the benefits outweigh the risks. Although it is an ongoing debate in the medical community to determine just exactly what those criteria should be.
How would a false positive create more harm? Isn’t it better to cast a wide net and detect more possible cases? Then false negatives are the ones that worry me the most.
It’s a common problem in diagnostics and it’s why mammograms aren’t recommended to women under 40.
Let’s say you have 10,000 patients. 10 have cancer or a precancerous lesion. Your test may be able to identify all 10 of those patients. However, if it has a false positive rate of 5% that’s around 500 patients who will now get biopsies and potentially surgery that they don’t actually need. Those follow up procedures carry their own risks and harms for those 500 patients. In total, that harm may outweigh the benefit of an earlier diagnosis in those 10 patients who have cancer.
Well it’d certainly benefit the medical industry. They’d be saddling tons of patients with surgeries, chemotherapy, mastectomy, and other treatments, “because doctor-GPT said so.”
But imagine being a patient getting physically and emotionally altered, plunged into irrecoverable debt, distressing your family, and it all being a whoopsy by some black-box software.
That’s a good point, that it could burden the system, but why would you ever put someone on chemotherapy for the model described in the paper? It seems more like it could burden the system by increasing the number of patients doing more frequent screening. Someone has to pay for all those docter-patient and meeting hours for sure. But the benefit outweighs this cost (which in my opinion is good and cheap since it prevents future treatment at later stages that are expensive).
Biopsies are small but still invasive. There’s risk of infection or reactions to anesthesia in any surgery. If 100 million women get this test, a 5% false positive rate will mean 5 million unnecessary interventions. Not to mention the stress of being told you have cancer.
5 million unnecessary interventions means a small percentage of those people (thousands) will die or be harmed by the treatment. That’s the harm that it causes.
You have really good point too! Maybe just an indication of higher risk, and just saying “Hey, screening more often couldn’t hurt.” Might actually be a net positive, and wouldn’t warrant such extreme measures unless it was positively identified by, hopefully, human professionals.
You’re right though, there always seems to be more demand than supply for anything medicine related. Not to mention, here in the U.S for example, needless extra screenings could also heavily impact a lot of people.


{kind=link}
Unfortunately AI models like this one often never make it to the clinic. The model could be impressive enough to identify 100% of cases that will develop breast cancer. However if it has a false positive rate of say 5% it’s use may actually create more harm than it intends to prevent.
Another big thing to note, we recently had a different but VERY similar headline about finding typhoid early and was able to point it out more accurately than doctors could.
But when they examined the AI to see what it was doing, it turns out that it was weighing the specs of the machine being used to do the scan… An older machine means the area was likely poorer and therefore more likely to have typhoid. The AI wasn’t pointing out if someone had Typhoid it was just telling you if they were in a rich area or not.
That’s actually really smart. But that info wasn’t given to doctors examining the scan, so it’s not a fair comparison. It’s a valid diagnostic technique to focus on the particular problems in the local area.
“When you hear hoofbeats, think horses not zebras” (outside of Africa)
AI is weird. It may not have been given the information explicitly. Instead it could be an artifact in the scan itself due to the different equipment. Like if one scan was lower resolution than the others but you resized all of the scans to be the same size as the lowest one the AI might be picking up on the resizing artifacts which are not present in the lower resolution one.
I’m saying that info is readily available to doctors in real life. They are literally in the hospital and know what the socioeconomic background of the patient is. In real life they would be able to guess the same.
The manufacturing date of the scanner was actually saved as embedded metadata to the scan files themselves. None of the researchers considered that to be a thing until after the experiment when they found that it was THE thing that the machines looked at.
That is quite a statement that it still had a better detection rate than doctors.
What is more important, save life or not offend people?
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Citation needed.
Usually detection rates are given on a new set of samples, on the samples they used for training detection rate would be 100% by definition.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.
What if one of those lower economic areas decides that the machine is too old and they need to replace it with a brand new one? Now every single case is a false negative because of how highly that was rated in the system.
The data they had collected followed that trend but there is no way to think that it’ll last forever or remain consistent because it isn’t about the person it’s just about class.
The goalpost has been moved so far I now need binoculars to see it now
That’s why these systems should never be used as the sole decision makers, but instead work as a tool to help the professionals make better decisions.
Keep the human in the loop!
Not at all, in this case.
A false positive of even 50% can mean telling the patient “they are at a higher risk of developing breast cancer and should get screened every 6 months instead of every year for the next 5 years”.
Keep in mind that women have about a 12% chance of getting breast cancer at some point in their lives. During the highest risk years its a 2 percent chamce per year, so a machine with a 50% false positive for a 5 year prediction would still only be telling like 15% of women to be screened more often.
Breast imaging already relys on a high false positive rate. False positives are way better than false negatives in this case.
That’s just not generally true. Mammograms are usually only recommended to women over 40. That’s because the rates of breast cancer in women under 40 are low enough that testing them would cause more harm than good thanks in part to the problem of false positives.
Nearly 4 out of 5 that progress to biopsy are benign. Nearly 4 times that are called for additional evaluation. The false positives are quite high compared to other imaging. It is designed that way, to decrease the chances of a false negative.
The false negative rate is also quite high. It will miss about 1 in 5 women with cancer. The reality is mammography is just not all that powerful as a screening tool. That’s why the criteria for who gets screened and how often has been tailored to try and ensure the benefits outweigh the risks. Although it is an ongoing debate in the medical community to determine just exactly what those criteria should be.
How would a false positive create more harm? Isn’t it better to cast a wide net and detect more possible cases? Then false negatives are the ones that worry me the most.
It’s a common problem in diagnostics and it’s why mammograms aren’t recommended to women under 40.
Let’s say you have 10,000 patients. 10 have cancer or a precancerous lesion. Your test may be able to identify all 10 of those patients. However, if it has a false positive rate of 5% that’s around 500 patients who will now get biopsies and potentially surgery that they don’t actually need. Those follow up procedures carry their own risks and harms for those 500 patients. In total, that harm may outweigh the benefit of an earlier diagnosis in those 10 patients who have cancer.
Well it’d certainly benefit the medical industry. They’d be saddling tons of patients with surgeries, chemotherapy, mastectomy, and other treatments, “because doctor-GPT said so.”
But imagine being a patient getting physically and emotionally altered, plunged into irrecoverable debt, distressing your family, and it all being a whoopsy by some black-box software.
That’s a good point, that it could burden the system, but why would you ever put someone on chemotherapy for the model described in the paper? It seems more like it could burden the system by increasing the number of patients doing more frequent screening. Someone has to pay for all those docter-patient and meeting hours for sure. But the benefit outweighs this cost (which in my opinion is good and cheap since it prevents future treatment at later stages that are expensive).
Biopsies are small but still invasive. There’s risk of infection or reactions to anesthesia in any surgery. If 100 million women get this test, a 5% false positive rate will mean 5 million unnecessary interventions. Not to mention the stress of being told you have cancer.
5 million unnecessary interventions means a small percentage of those people (thousands) will die or be harmed by the treatment. That’s the harm that it causes.
You have really good point too! Maybe just an indication of higher risk, and just saying “Hey, screening more often couldn’t hurt.” Might actually be a net positive, and wouldn’t warrant such extreme measures unless it was positively identified by, hopefully, human professionals.
You’re right though, there always seems to be more demand than supply for anything medicine related. Not to mention, here in the U.S for example, needless extra screenings could also heavily impact a lot of people.
There’s a lot to be considered here.
deleted by creator